Size Measurement for the Vintage Computing Christmas Challenge
Code size measurement
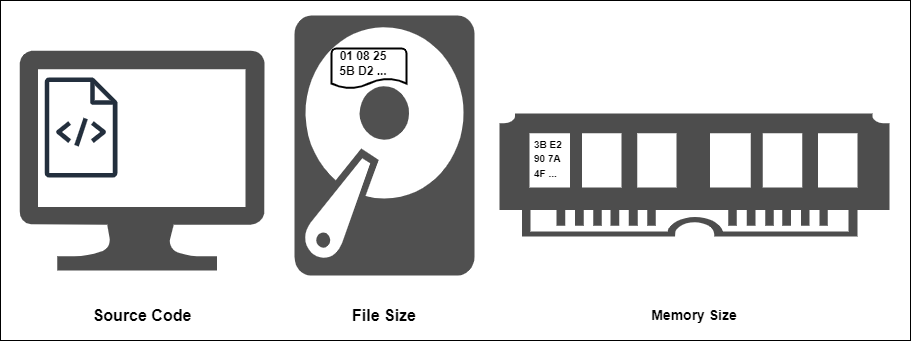
You can measure the code in different ways. These are:
- Size of source code
- File size
- Net file size / used memory.
This page gives you a quick overview. For details, refer to filesize details, VCCC FAQ and the rules itself.
Source file
The size of the (mostly human-readable) source code. Usually a text file with a different ending.
Examples
- .c
- .bas
- .pas
- ...
Hints
- You can save the source code of any language yourself using a standard text file. This is especially helpful, as some languages save their code in a special format. For example, BASIC often saves source code in a tokenized format.
- You may use CR instead of CRLF.
- Use the file size 1:1.
Executable File size
The size of the runnable file. Usually that's compiled code.
Examples
- .exe, .com (PC)
- .xex (Atari)
- .prg (Commodore)
- .bin (several platforms)
- ...
Hints
- These files often contain metadata.
- Some systems don't measure in bytes (but blocks or similar). In this case, it is useful to use a file format stored on PCs.
- Use the file size 1:1.
Actual code (net code size)
The size of the executable file minus metadata/"overhead".
Executable size
- File Header
- Start address
- BASIC stub
After subtracting, only the "pure code" should be left.